本文原载于https://imlogm.github.io,转载请注明出处~
摘要:最近使用Xception时发现效果很好,所以打算介绍下整个Inception系列。
关键字:深度学习, Inception, Xception, GoogLeNet
1. 从模型结构说起
其实关于Inception的结构,以及各代的改进,大家可以看这篇文章:深入浅出——网络模型中Inception的作用与结构全解析-深度学习思考者
有同学可能要说,上面链接里的那篇文章这么简单,似乎没讲太多内容。其实因为Inception每代之间联系性比较强,所以看明白了其中一篇,其他的也都能很快懂。如果要我来讲的话,大概会是下面四行字:
- GoogLeNet(Inception-v1):相比AlexNet和VGG,出现了多支路,引入了1×1卷积帮助减少网络计算量
- Inception-v2:引入Batch Normalization(BN);5×5卷积使用两个3×3卷积代替
- Inception-v3:n×n卷积分割为1×n和n×1两个卷积
- Inception-v4:进一步优化,引入ResNet的shortcut思想
个人体会:v1和v2中的改进对深度学习的发展具有非常大的意义;v3有一点创新,但开始出现“炼丹”的感觉;v4参考ResNet说明ResNet的思想确实牛逼,其他部分完全在“炼丹”,网络过于精细,不容易迁移到其他任务中
推荐大家在训练模型时尝试使用Inception-v2中出现的Batch Normalization(BN),关于BN的原理,可以看我上一篇文章:Batch Normalization(BN)
2. Xception
之所以把Xception单拎出来说,一是因为Xception比较新,上面那篇文章没有讲到;二是因为Xception设计的目的与Inception不同:Inception的目标是针对分类任务追求最高的精度,以至于后面几代开始“炼丹”,模型过于精细;Xception的目标是设计出易迁移、计算量小、能适应不同任务,且精度较高的模型。
那么Xception与Inception-v3在结构上有什么差别呢?
如图1为Inception-v3的模块结构,依据化繁为简的思想,把模块结构改造为图2。
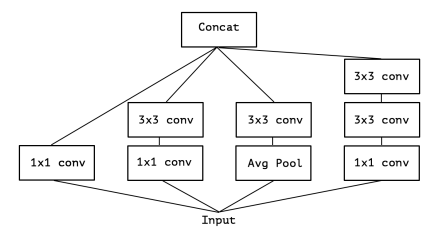

依据depthwise separable convolution的思想,可以进一步把图2改造到图3。
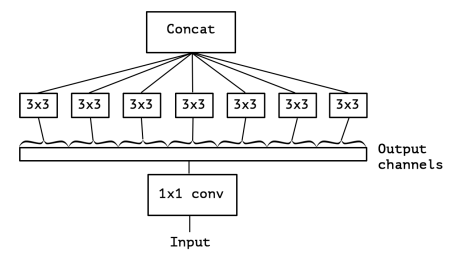
什么是depthwise separable convolution呢?MobileNet等网络为了减少计算量都有用到这个方法,不过Xception在这里的用法和一般的depthwise separable convolution还有点不同,所以为了防止大家搞糊涂,我就不介绍一般性的用法了,直接介绍Xception中的用法。
对于112×112×64的输入做一次普通的3×3卷积,每个卷积核大小为3×3×64,也就是说,每一小步的卷积操作是同时在面上(3×3的面)和深度上(×64的深度)进行的。
那如果把面上和深度上的卷积分离开来呢?这就是图3所要表达的操作。依旧以112×112×64的输入来作例子,先进入1×1卷积,每个卷积核大小为1×1×64,有没有发现,这样每一小步卷积其实相当于只在深度上(×64的深度)进行。
然后,假设1×1卷积的输出为112×112×7,我们把它分为7份,即每份是112×112×1,每份后面单独接一个3×3的卷积(如图3所示,画了7个3×3的框),此时每个卷积核为3×3×1,有没有发现,这样每一小步卷积其实相当于只在面上(3×3的面)进行。
最后,把这7个3×3的卷积的输出叠在一起就可以了。根据Xception论文的实验结果,Xception在精度上略低于Inception-v3,但在计算量和迁移性上都好于Inception-v3。
3. 关于模型复杂度的计算
其实这部分内容我本来打算重点写的,为此我还特地写了篇“以VGG为例,分析模型复杂度”的文章。(+﹏+)~ 可是,就在写那篇文章的时候,我发现了一篇对Inception的复杂度计算介绍得非常清晰的文章。那我就偷个懒,大家可以直接看这篇文章的后半部分:卷积神经网络的复杂度分析-Michael Yuan的文章